
A Vestibule For Expansion
The First 3 Weeks of My Internship

A Vestibule For Expansion
April 16th, 2018, A young bare faced boy jaunted into his new workplace. Greeted warmly, he proceeded to receive a tour of this strange new environment. After a brief overview of the facility, he was led to his new office. Yes, his very own office. With his own computer, and desk. This was a monumentally novel experience. To have ones own office was indeed strange, yet added only to the excitement of the experience. This very office, in all reality a repurposed storage room, would soon come to be known as the Vestibule for Expansion. Indeed a vestibule in that it was an entryway, and by expansion, it is meant an expansion of the mind, heart, and beard of that youthful soul that had entered in. I am that youth, and it is my hope that throughout this blog you and I both will see the change that I go through as I’m having my first real experience in data science.
Of Course I Know How To SQL
My very first task I needed to accomplish was to connect my trusty R-Studio to the database I would be working with. After downloading all of my programs, and the packages I thought I would need, I went to work googling how to connect to the SQL Database the company had. Soon I found the odbc package which allowed me to connect. I showed the package to the database coordinator that I was working with, and he soon provided me the connection string I needed to log in. After some finagling, and trying to find relevant tables amongst hundreds, I managed to pull my first dataset off of the SQL server. It only had 15 million rows of data. This was daunting. I was overwhelmed. I went to work cleaning my data, and quickly learned that cleaning 15 million rows of data using dplyr functions was painfully slow. After a small amount of tidying I decided I just needed to make some sort of graphic to show that I was making even a marginal amount of progress. So I created some graphic with inaccurate data because I honestly didn’t know what i was doing. I was overwhelmed and the task in front of me seemed impossible.
“Calculating P-Values is just silly”
Once I had managed to figure out how to load, and clean my data, I started trying to run some tests. I ran some Chi squared, and Logistic regression tests, and realized I was getting some rather strange p-values. I thought I needed to normalize my data, but wasn’t sure. I emailed one of my professors from school about it, and he informed me that calculating p-values for 15 million rows of sample data was just silly. With that simple statement, all hope was shattered. I sat at my desk, a mere shell of the confident, eager data student I had been when I accepted this internship. What purpose did I have? If I didn’t have statistics I figured I had nothing. It was then I realized I would have to teach myself how to build machine learning algorithms, and learn how to build machine learning algorithms is exactly what I did.
Despair Is The Driver Of Determination
I turned to the internet. I read about decision trees, and random forests. I experimented with K-means and clustering. I was comprehensively confused. While I understood the basic ideas behind these algorithms, and how to train a model. However the task of choosing a model, and learning about it’s hyperparameters, and how to effectively sample my data was absolutely overpowering. My confidence at this point was at a low. Maybe data science wasn’t my thing. I loved making visualizations, and doing statistics, but this was beyond my breadth. I sunk into despair. At this point it was about time for my lunch break, and being down I decided that I deserved to go out to eat. I proceeded to make the five minute journey to Panda Express, and while eating my orange chicken I made a decision. I was going to learn. I no longer cared how little I knew, or how badly I wanted to succeed. All that mattered to me from that point was how interesting and incredible the machine learning algorithms I was learning were. From that point I gained a vigor for learning, and felt a new life in my work.
Growing Forests and Taking Names
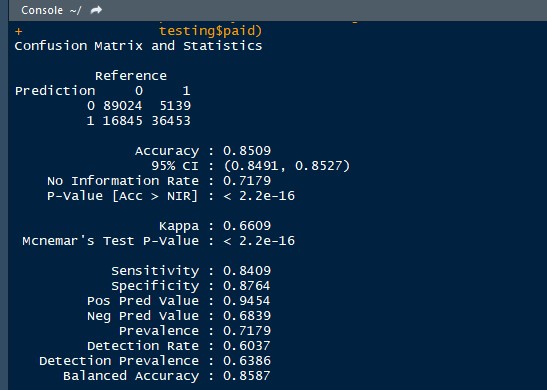
After several DataCamp courses, and a few practice datasets from Kaggle, I managed to use the Caret package to create several different models for my data. After comparing the results of my validation sets, I decided on using a Random Forest as my preferred model as it had the optimal performance of the spread. I then learned about cross validation, and tuning the mtry parameter of the algorithm. I learned about sampling methods and Pre-Processing. After several days of work I managed to create a working Random Forest that could predict my test set with 85% accuracy. I was elated. I told my friends, I posted about it on LinkedIn and felt so accomplished. After several more days of tuning, and adjusting my training data, I made a much more robust model that continues to have an 85% accuracy rate across multiple testing sets. I had done it.
Moving Forward
From this point my next objectives are to go over my work and make sure I hadn’t make any mistakes, and then to find a way to extract my forest, and implement it with the company. I have found a way to export it, and reprogram it using c#. That will be a massive undertaking I think, but at this point I’m ready and excited. I will continue making posts describing some of the problems I’ve run into and how I managed to solve them. I feel like starting this internship was an entire lifetime ago considering everything I’ve learned, and how I’ve grown, and I’m looking forward to the next few months with optimism as I move forward.

Share this post
Twitter
Facebook
Reddit
LinkedIn
Pinterest
Email