

A statistical approach to discerning adversarial attacks
The report on the research I did at ORNL

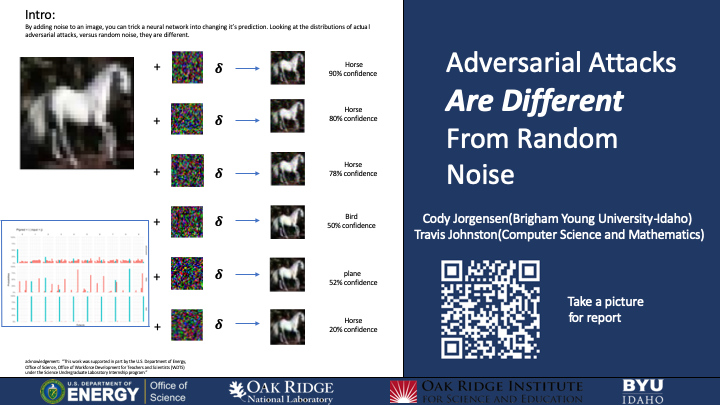
A neural network is a computer algorithm that uses calculus to, make predictions from a given set of parameters, either as a number(linear regression) or as a class(classification). One of the most useful cases of a Neural network is in image classification. In this project we use a statistical approach to identify the differences between white box adversarial attacks, black box adversarial attacks, and random noise. An adversarial attack consists of changing the pixels of input images to change a neural network’s prediction. We created example attacks by computing the gradient of the image with respect to the loss function, to effect the greatest change in output with the least amount of change to input.We subtracted the gradient from the original image multiple [SM1] times, generating an image that is not visually distinct from the original image. In this way we change the image using what is known about the network from the gradient. We created 10,000 of these adversarial examples, and to 10,000 of the original images we added random noise. We then compared the distribution of the neural network’s classification on the noise-modified images, the adversarial images , and the original images. We found that the adversarial succeeded directly 74% of the images, and indirectly in 10% of images. Leaving only 16% accuracy. The randomly perturbed images succeeded to alter the output 74% of the time leaving 26% accuracy, with the model being 98% accurate on the original. The distributions of the random predictions however came from a much more random distribution, whereas the adversarial attacks were extremely uniform in their error rates. This research will aid in identifying adversarial attacks on commercial networks, such as self driving cars, or facial image recognition. Future work will focus on how these results scale to deeper and more complex networks, as well as images. To a human being the word apple has a specific meaning. We imagine a red fruit, that’s somewhat circular. But sometimes they are green. Sometimes misshapen, yet human beings are still able to identify an apple. Advancements in technology have led to us attempting to create computers that can make similar classifications. Although for some of the same reasons as above, it can be very difficult. Convolutional neural networks are the current tool used in most image classification. Convolutional neural networks aren’t able to see an image as colors and shapes, merely as numbers. Yet they are able to extract certain features from images such as edges, and regions of intensity to make a classification.By making small, seemingly insignificant changes to these features, you can change the classification of the network. To humans, the difference between an apple and a horse is very distinct, but to a neural network, the difference could be merely three or four pixels. Most sensors and data collection systems have a degree of noise that is merely part of an imperfect sensor. In my research, I embarked on a quest to discover what is the stochastic difference between an image that incorrectly classified something due to random noise, and those that were adversarially attacked. As this is not only a report on my research, but also my overall experience as a SULI participant I will also include several research topics that I did not have the time to complete. Methods: Using a multilayer convolutional neural network, with several relu layers, I trained on the MNIST dataset. After training I needed to decide on a way to create and add random noise to the images. I decided to create an image of the same size as the original, randomly generated with a uniform distribution between -1 and 1. I would then take this image, and multiply it by a delta (.01) and add it to the original image. This would slightly blur the image without changing the shape. I used a testing set of 10,000 images, creating random examples with a set seed for each. Next came creating my adversarial attacks. There are two general classes of attacks. White box attacks which imply that you have access to what the network looks like, and can access data throughout it. Black box attacks imply the opposite; having no access to how the network is built, only having the outputs as ammunition. After creating the random noise, with the exact same images I used a white box attack to create directed adversarial attacks. The way back propagating neural networks work is by taking the partial derivative of the weights of each layer, with respect to the loss function, and using that partial derivative, or gradient, to adjust the weights. In my white box attack, I would compute the partial derivative of the pixel values of the image with respect to the loss function, but with an incorrect label. I would then add this adversarial gradient, multiplied by some delta (.01) to change the image, so that the network would be more likely to be classified as the target. For the adversarial examples I took each of my 10,000 testing images, and used my white box attack recursively for each image 50 times, meaning I would compute the gradient, and add it to the image, and then take my new image and repeat the process 50 times. I did this for each of my 10 targets, creating a total of 100,000 different adversarial images, each coming from the same 10,000 original testing images. Then I compared the histograms of the softmax outputs of my networks. Originally my Neural Network predicted with 98% accuracy on the testing dataset. But with my random samples, it now was only 26% accurate. Using my adversarial data, my neural network was only correct 16% of the time. Simply looking at the numbers you can see that 26% and 16% is different, but when it comes to the credibility of the model, dropping from 98% to either number has the same effect. It effectively causes the model to be useless. Simply seeing a drop in accuracy in a network could come from a variety of things, from sensor noise, to new types of data. Not necessarily an adversarial attack. I originally hypothesized that the histograms of the softmax outputs would be stochastically different depending on if they were random, or adversarial examples. More scientific methods of determining if they are different such as a Chi-squared test, or other tests of distributions are available, but I was not able in my limited time to perform them. So I based my conclusions upon what I could see. When I created the histograms, I found that the adversarial examples seemed to come from more of a uniform distribution. The random examples were much more random in their distributions. It was very obvious to see that there was a difference. So let’s say that some brilliant ecological scientist developed a network to identify different types of birds in an area to study the effects of a new power plant on wildlife. This scientist suddenly notices a large change in the consistency of birds it identifies. The scientist would have several conclusions they would have to work through. The birds could actually be different, being a monumental breakthrough in their study. The camera may have been slightly damaged, warranting a repair or replacement. Or perhaps the owners of the powerplant do not want the truth to be uncovered, and have used an adversarial attack to try and support what they want your conclusion to be. With my results, by looking at the distributions of the outputs, you could tell which was the true case, and take appropriate actions. Given the short period of my research there are many ideas that I had that I wasn’t able to fully develop. For the rest of my paper I will discuss some of those thoughts, and further research that I will be doing in the future. I found that using such a simple dataset, with such a shallow network as I have been using (Less than 10 layers), the random noise needed to be quite extreme in order to produce images that were misclassified. Extreme enough that it was visible to the human eye. The random noise was created from a uniform distribution between -1 and 1. However, I believe that a better way to generate the random noise would be from a normal distribution of mean 0, and standard deviation .5 with an afterwards clamping of the data so that it remains between 0 and 1. (Which is the range of our testing data) I also believe that using a more complex neural network, along with more complex images such as imagenet, or maybe even just one of the CIFAR datasets would yield results that are less visually apparent to the human eye. Along this same path, I would love to create my own dataset of images, and train them on a network. Then rather than adding artificial noise, slightly change the focus of the camera on another set of images. Thus making a more practical application of noise that would be present in a real life scenario. Then I would create adversarial attacks of my own and compare them. Another problem with my research that I want to elaborate on is the one dimensional approach to my attacks. I used only a white box gradient approach to create my adversarial examples. I am vaguely aware of other approaches such as the one or two pixel attacks, as well as several other white and black box approaches. In my eventual goal of creating neural networks that are more robust to attacks, my solution would need to be able to detect multiple types of attacks. On a similar note, I mentioned earlier that my approach in creating my attacks was to recursively take the gradient 50 times. This doesn’t sit right with me. I want to do some research and prove whether or not taking the gradient recursively 50 times is not the same as multiplying my delta by 50. In my mind the gradient would be the same for each image. Perhaps changing in magnitude, but not in direction. The reason that I share all of these ideas in this paper is because there is much more work for me to do than I could possibly begin to understand in the short 10 weeks I had at Oak Ridge National Laboratory. I couldn’t find 1500 words of what I’ve done to share, and much rather than fluff what I have, I’d rather share about what I’m excited to continue to do. This opportunity has fueled my scientific spirit. I will continue to go on and research. All code for my research can be accessed via my github repository. However it is extremely messy. I’m sorry for that.

Twitter
Facebook
Reddit
LinkedIn
Pinterest
Email